Emission-factor matching is a reasoning problem, not a database lookup
Discover this blog post
Carbon+Alt+Delete benchmarked three state-of-the-art emission-factor matching algorithms on a realistic procurement dataset. The goal was to understand which matching approach performs best in practice and what characteristics separate high-quality matching from poor matching. The results show that reasoning-based approaches outperform traditional retrieval-based approaches, with open-climate.ai achieving the strongest overall performance.
Introduction
Emission factor (EF) matching is one of the most important and time-consuming steps in carbon accounting, in particular for scope 3 data. Procurement data is messy, product descriptions are ambiguous and manually selecting the right emission factor often requires significant domain expertise. Recent advances in AI have made it possible to automate much of this work, making AI-powered EF matching the most promising path forward for scaling high-quality carbon accounting.
But adopting AI introduces a new challenge: how do you evaluate the quality of an EF matching algorithm? Unlike traditional software, AI systems will almost always return an answer. The real question is whether that answer is correct, defensible, and usable. A model that confidently selects the wrong factor can create more work than it saves, while a model that reasons carefully about context, materials, units, and uncertainty can dramatically reduce manual review effort.
In this blog, we explore why EF matching is fundamentally a difficult problem, and how matching quality should be assessed in practice. We then present the results of a benchmark comparing three different EF matching approaches, examining not only whether they find a factor, but whether they find the right factor and return it in a form that can be applied directly.
Matching is reasoning, not retrieval
This is the whole thesis, so we'll put it first. EF matching is the process of taking a procurement line, such as a purchase order, invoice line, or spend record, and identifying the emission factor that best represents the product or service being purchased. AI can do so by assessing the similarity between the words in the procurement line and emission factor.
A similarity matcher is only as good as the text overlap between a procurement line and a factor name. That overlap is exactly what real procurement data breaks: brand codes
share no words with the material, jargon means nothing to a search box, waste-named activities look textually identical to virgin inputs, and a perfect factor name is useless if it's priced in the wrong unit.
An agent that reasons decodes Moplen to polypropylene before it searches, rejects a fertiliser when the line means liquid nitrogen the industrial gas, prefers steel production over scrap treatment, and turns 2,400 litres of oil into the kilograms the factor expects. It's the judgement a consultant applies by hand, done consistently, at file scale, with every assumption logged.
Bigger databases help: more sources mean more chances the exact factor exists somewhere. But coverage and matching are different problems. Having the right factor in the catalogue doesn't help if the tool can't tell which line it belongs to or returns it in a unit the line can't use.
Why is it harder than it looks
The difficulty lives in the data. A few of the traps when matching emission factors with procurement ledgers:
· Opaque, context-dependent columns. A line often only makes sense considering the whole file: the supplier, the other items, what the company does. A cryptic code or bare part number is decipherable once you've read the rest of the sheet and inferred the business context, and meaningless once you look at it row by row. That context is what a human usually has and is what a line-by-line matcher throws away.
· Brand and trade names. Lexan, Zamak, Moplen are meaningless as text, but they're polycarbonate, a zinc alloy, and polypropylene.
· Industry jargon. Codes, grades, and technical terms that mean one specific material to an engineer and nothing to a search box.
· Units that don't line up. Water is bought in m³, oil in litres but the emission factors are available per kg. The correct factor in the wrong unit is useless until someone converts it.
· Same word, different thing. Liquid nitrogen is an industrial gas, not a nitrogen fertiliser. A kraft liner is paperboard, not a steel liner.
· Virgin vs waste. A steel coil you buy is steel production, not scrap steel treatment, a completely different number.
And getting the material name right is only half the job. A library like ecoinvent carries dozens of variants of the "same" material, differing by production route and geography. "Steel" spans primary blast-furnace and recycled electric-arc steel, whose factors differ several-fold; "electricity" swings wider still between a hydro grid and a coal one. Pick the wrong variant and you get a quietly wrong number, not an obvious miss
How to assess the quality of EF matching
AI matching can always find a match, that’s the nature of generative AI. At the same time, EF matching does not have 1 correct solution. Several experts might match the same procurement line with a different emission factor. So the question is how to assess the quality of AI-enabled EF matching.
We assess the quality based on 2 criteria:
- Direct usability: Does the factor come in a unit corresponding with the procurement data you have? If not, then the matching does not save you time.
- Quality. What is the quality of the match, grouped into 4 batches?
- Excellent: right material, right specificity.
- Acceptable: a defensible in-family proxy.
- Wrong: wrong material or category, or a waste/recycling factor for a virgin input.
- No result.
Comparing the quality of 3 EF matching algorithms
We ran 3 state-of-the-art systems on the same realistic procurement ledger: open-climate.ai and 2 commercially available algorithms. The quality of the matching was assessed by a human expert in combination with an AI agent built to assess the quality of EF matches.
The table below shows the results. It indicates clearly that open-climate.ai outperforms the other algorithms, both on direct usability and quality.
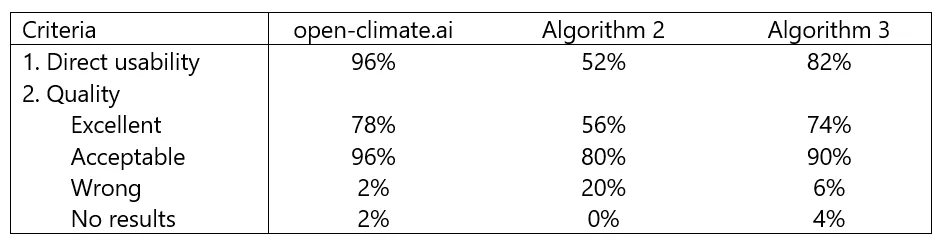
The test was run on an anonymized but actual procurement file of 50 lines. It included the typical difficulties mentioned above: plainly-named commodities, brand and trade names that need decoding, collision and waste traps, and a mix of units (kg, litres, m³, item counts). The dataset is intentionally small, but it reflects real manufacturing procurement files and concentrates the exact classes of ambiguity that drive manual review effort. Open-climate.ai was matching this procurement file with ecoinvent emission factors. The 2 other algorithms were matching ecoinvent and other databases.
What the numbers say
- Direct usability is the number that matters. Nobody computes a footprint from semantic similarity; they compute it from a factor that fits the line. Algorithm 2’s 80% right-family matches collapse to 52% once the factor has to fit the line's unit. It returned spend-based factors in foreign currencies against lines measured in kilograms, and left litre and m³ lines priced per kilogram. Open-climate.ai converts the quantity into the factor's unit, so the match can be applied on 96% of lines.
- Coverage didn't decide it. To separate matching skill from catalogue size, we also ran algorithm 2 on the same single library, ecoinvent, and its quality dropped sharply (0% excellent, 84% wrong). That number looks extreme, so here's the mechanism: stripped of its broad spend-based and EPD sources, a retrieval matcher has nowhere to fall back to, so it returns the nearest text neighbour, and in ecoinvent the nearest text neighbour to a virgin material is often its waste- or scrap-treatment activity, which carries a completely different number. It isn't a fluke; it's what pure retrieval does when breadth stops papering over it.
- Trust is the point of automating. Time saved only holds if you can trust the tool enough not to re-check every line. open-climate.ai flagged its single wrong pick for review, so attention goes only to the lines it's unsure about. A tool that ships wrong matches at high confidence forces a full manual pass over thousands of lines, which is the work you were trying to avoid. Final note: All benchmarking data can be requested on [email protected] (i.e., procurement file, raw outputs, and the line-by-line). We invite readers to re-run it, re-grade it, disagree with us, and send us the messiest procurement file you have to try it on your data.
About Carbon+Alt+Delete
We provide carbon accounting software for sustainability consultants and consultancies that guide companies towards net zero.
Curious to discover how our software can improve your carbon accounting services?
Feel free to reach out to [email protected] or book a meeting to talk to one of our experts here.